< Conteúdo >
![]()
Regressão à média¶
Regressão à média (regression to the mean) é um fenômeno estatístico que ocorre sempre que:
- você trabalha com uma amostra não aleatória extraída da população
- e duas variáveis imperfeitamente correlacionadas (correlação diferente de $1$ ou diferente de $-1$) são medidas, por exemplo, duas medições consecutivas da pressão arterial.
Quanto menos correlacionadas as duas variáveis, maior o efeito da regressão para a média. Além disso, quanto mais extremo for o valor da média da amostra não aleatória (quando comparada com a média da população), mais espaço haverá para regredir à média.
Mas para entendermos com maior clareza as frases anteriores, e o que é regressão à média (regression to the mean), vamos recorrer a um pouco de história e a um exemplo.
Francis Galton e o fenômeno de regression towards mediocrity¶
A primeira pessoa que descreveu e explicou o fenômeno de regressão à média (regression to the mean) foi Sir Francis Galton em 1886. Galton foi pioneiro na aplicação de métodos estatísticos para realização de medições em muitos ramos da ciência e, ao estudar dados sobre os tamanhos relativos entre pais e filhos em várias espécies de plantas e animais, ele observou o seguinte fenômeno:
- Um pai cuja altura é maior do que a média da sua geração tende a produzir um filho cuja altura também será maior do que a média da sua geração, no entanto, é provável que a altura do filho não se destaque tanto quanto a do pai em termos relativos dentro de suas próprias gerações.
- Em outras palavras, se a altura do pai está a $x$ desvios padrão da média dentro da sua própria geração, deve-se esperar que a altura do filho esteja a $rx$ desvios padrão da média dentro do conjunto de filhos desses pais, onde $r$ é um número menor do que $1$ em magnitude.
Galton denominou esse fenômeno de regression towards mediocrity, conhecido altualmente como regressão à média (regression to the mean). Para um observador ingênuo, isso pode sugerir que as gerações posteriores exibirão menos variabilidade (literalmente mais mediocridade) do que as anteriores, mas esse não é o caso. Trata-se de um fenômeno puramente estatístico, já iremos entender o porquê.
Uma explicação intuitiva¶
A explicação intuitiva para o efeito da regressão à média (regression to the mean) é pensar em termos de viés de seleção. Em geral, o desempenho de um jogador durante um determinado período de tempo pode ser atribuído a uma combinação de habilidade com sorte. Suponha que selecionamos uma amostra de atletas profissionais cujo desempenho foi muito melhor do que a média (ou estudantes cujas notas foram muito melhores do que a média) na primeira metade do ano. O fato de terem se saído tão bem no primeiro semestre torna provável que suas habilidades e sorte tenham sido melhores do que a média durante esse período. No segundo semestre, podemos esperar que sejam igualmente habilidosos, mas não devemos esperar que tenham a mesma sorte. Portanto, devemos esperar que no segundo semestre o desempenho deles esteja mais próximo da média. O mesmo vale para os jogadores com desempenho muito pior do que a média na primeira metade do ano. O fato de terem se saído tão mal no primeiro semestre torna provável que suas habilidades e sorte tenham sido piores do que a média durante esse período. No segundo semestre, podemos esperar o mesmo nível de habilidade do primeiro semestre, mas não devemos esperar que tenham a mesma sorte (ou neste caso, o mesmo azar). Portanto, também devemos esperar que no segundo semestre o desempenho deles esteja mais próximo da média. Na prática, o desempenho real dos jogadores deve ter uma variação igualmente grande tanto no primeiro semestre quanto no segundo, pois esta variação resulta meramente de uma redistribuição da sorte (que é aleatória e independente) entre os jogadores (que continuam possuindo a mesma distribuição de habilidades de antes).
Outra maneira de pensar no efeito da regressão à média (regression to the mean) é o seguinte: tipicamente, tudo o que tentamos prever consiste em uma componente previsível (o sinal) e uma componente imprevisível (o ruído) que é estatisticamente independente. O melhor que podemos esperar é prever (apenas) a parte da variabilidade que é devida ao sinal. Portanto, as nossas previsões tenderão a exibir menos variabilidade do que os valores reais observados, o que implica em uma regressão à média (regression to the mean).
Um exemplo numérico¶
Primeiramente, vamos criar $3$ variáveis aleatórias:
- $\text{rv_skill} \sim N \left(\mu=50, \sigma=10 \right)$: uma para representar a habilidade dos jogadores (
rv_skill) tanto no primeiro quanto no segundo semestre (estamos assumindo que a habilidade dos jogadores não sofrerá grandes ou quaisquer modificações entre um semestre e outro). Representaremos esta variável aleatória através de uma distribuição normal com média $\mu=50$ e desvio padrão $\sigma=10$. - $\text{rv_luck_period1} \sim N \left(\mu=0, \sigma=5 \right)$: uma para representar a sorte dos jogadores no primeiro semestre (
rv_luck_period1), através de uma distribuição normal com média $\mu=0$ e desvio padrão igual a $\sigma=5$. - $\text{rv_luck_period2} \sim N \left(\mu=0, \sigma=5 \right)$: uma para representar a sorte dos jogadores no segundo semestre (
rv_luck_period2), através de uma distribuição normal com média $\mu=0$ e desvio padrão igual a $\sigma=5$.
Vamos supor que a nossa população seja composta por $500$ jogadores.
from scipy import stats as st
rv_skill = st.norm(loc=50.0, scale=10.0)
rv_luck_period1 = st.norm(loc=0.0, scale=5.0)
rv_luck_period2 = st.norm(loc=0.0, scale=5.0)
pop_size = 500
pop_skill = rv_skill.rvs(size=pop_size)
pop_luck_period1 = rv_luck_period1.rvs(size=pop_size)
pop_luck_period2 = rv_luck_period2.rvs(size=pop_size)
A simulação dos experimentos que representam a medição das habilidades da nossa população de jogadores no primeiro (pop_measure_period1) e no segundo (pop_measure_period2) semestre é realizada através do código abaixo.
Vale lembrar que as habilidades são medidas através das informações que são observadas no mundo real, portanto, serão compostas de uma componente de habilidade real (o sinal) e uma componente de sorte (o ruído).
pop_measure_period1 = pop_skill + pop_luck_period1
pop_measure_period2 = pop_skill + pop_luck_period2
Vamos verificar algumas estatísticas da nossa população de jogadores.
import pandas as pd
df = pd.DataFrame({
'skill': pop_skill,
'luck1': pop_luck_period1, 'luck2': pop_luck_period2,
'skill_measure1': pop_measure_period1, 'skill_measure2': pop_measure_period2
})
df.describe()
O esperado é que a média da variável que representa a habilidade real dos jogadores (skill) seja próxima de $50$ e as médias das componentes que representam a sorte (no primeiro e segundo semestres, luck1 e luck2) sejam próximas de $0$.
Vamos verificar as distribuições das duas (primeiro e segundo semestre) medições de habilidades (skill_measure1 e skill_measure2) e checar se o formato das mesmas parece uma normal.
df.hist(column='skill_measure1')
df.hist(column='skill_measure2')


Os histogramas devem se assemelhar à curva normal. Além disto, as variáveis que representam as duas medições são correlacionadas, uma vez que possuem a mesma componente da habilidade real dos jogadores.
r = st.pearsonr(pop_measure_period1, pop_measure_period2)
print("Correlation beetwen skill_measure1 and skill_measure2 = {0}".format(r[0]))
print("p-value of correlation = {0}".format(r[1]))
Não esperamos que sejam perfeitamente correlacionadas, uma vez que a componente de sorte é aleatória e independente entre os semestres. Abaixo o gráfico que representa a distribuição bivariada das medições.
import altair as alt
alt.renderers.enable('notebook') # for the notebook only (not for JupyterLab) run this command once per session
# scatter plot of dataset
df_plot = alt.Chart(df).mark_point().encode(
alt.X('skill_measure1:Q', scale=alt.Scale(zero=False)),
y='skill_measure2:Q',
size=alt.value(10)
).properties(title="bivariate distribution of skill_measure1 and skill_measure2")
df_plot

Como já mencionado aqui,
Regressão à média (regression to the mean) é um fenômeno estatístico que ocorre sempre que você trabalha com uma amostra não aleatória extraída da população e duas variáveis imperfeitamente correlacionadas (correlação diferente de $1$ ou diferente de $-1$) são medidas, por exemplo, duas medições consecutivas da pressão arterial. Quanto menos correlacionadas as duas variáveis, maior o efeito da regressão para a média. Além disso, quanto mais extremo for o valor da média da amostra não aleatória (quando comparada com a média da população), mais espaço haverá para regredir à média.
ou seja, regressão à média (regression to the mean) tende a ocorrer sempre que selecionamos um grupo extremo da população.
Então suponha que a nossa amostra não aleatória represente o grupo de jogadores cuja habilidade tenha sido menor do que $50$ no semestre 1, ou seja, menor do que a média da população.
# função para filtrar as linhas do data frame
def filter_df(filter_param, df):
filtered_df = df[filter_param]
filtered_df = filtered_df.rename(columns = {
'skill':'sample_skill',
'luck1':'sample_luck1', 'luck2':'sample_luck2',
'skill_measure1':'sample_skill_measure1', 'skill_measure2':'sample_skill_measure2'})
return filtered_df
is_skill_measure1_below_50 = df['skill_measure1'] < 50
df_skill_measure1_below_50 = filter_df(is_skill_measure1_below_50, df)
df_skill_measure1_below_50.head()
O que fizemos nos passos anteriores foi gerar uma amostra (a partir da nossa população) que compreende apenas jogadores tais que $\text{skill_measure1} < 50$. Trata-se de uma amostra não aleatória.
Então, se para apenas esta amostra de jogadores compararmos o desempenho deles entre o primeiro e segundo semestres (sample_skill_measure1 e sample_skill_measure2), teremos:
df_skill_measure1_below_50[['sample_skill_measure1', 'sample_skill_measure2']].describe()
Ao analisar os dados anteriores, a primeira impressão é a de que o desempenho dos jogadores melhorou um pouco do primeiro semestre para o segundo semestre (a média da medição do segundo semestre é um pouco maior do que a do primeiro). Isto significa que os jogadores ficaram mais habilidosos no segundo semestre? Que essa melhoria é apenas uma maturação normal em virtude dos treinos? Provavelmente, não! O que você está testemunhando aqui é o efeito da regressão à média (regression to the mean).
Foi selecionado um grupo de jogadores que apresentaram um baixo desempenho na medição do primeiro semestre ($\text{skill_measure1} < 50$). Então, para qualquer outra medição que estiver imperfeitamente correlacionada com a medição do primeiro semestre, este grupo de jogadores parecerá ter um desempenho melhor, simplesmente por causa da regressão à média (regression to the mean). Note que a habilidade real (sample_skill) destes jogadores permanece a mesma tanto no primeiro quanto no segundo semestre, já a componente da sorte, não é a mesma entre o primeiro e segundo semestres (sample_luck1 e sample_luck2).
Veja as distribuições das medições no primeiro e segundo semestres do grupo de jogadores pertencentes à amostra.
df_skill_measure1_below_50.hist(column='sample_skill_measure1')
df_skill_measure1_below_50.hist(column='sample_skill_measure2')


Observe que o histograma sample_skill_measure1 da nossa amostra de jogadores se assemelha à metade esquerda da curva normal, o que já era esperado uma vez que selecionamos apenas os jogadores da metade inferior ($\text{skill_measure1} < 50$) da medição do primeiro semestre da nossa população.
Já, o histograma sample_skill_measure2 não parece tão claramente cortado ao meio. Por que não? A habilidade real (sample_skill) destes jogadores permanece a mesma tanto no primeiro quanto no segundo semestre. Logo, isto deve ter relação com a componente da sorte, que não é a mesma entre o primeiro e segundo semestres (sample_luck1 e sample_luck2).
Obviamente, como todos os jogadores possuem a mesma habilidade (sample_skill) nas duas medições e, como os jogadores parecem, em média, ter um desempenho um pouco melhor na medição do segundo semestre (sample_skill_measure2) do que na do primeiro (sample_skill_measure1), devemos esperar mais componentes de sorte negativas na medição sample_skill_measure1 do que na medição sample_skill_measure2. Vamos verificar se isto é verdade.
import numpy as np
def count_neg_zeros_pos(array):
is_negative = array < 0.0
is_positive = array > 0.0
negatives = np.sum(is_negative)
positives = np.sum(is_positive)
zeros = pop_size - negatives - positives
return negatives, zeros, positives
sl1 = count_neg_zeros_pos(df_skill_measure1_below_50['sample_luck1'])
sl2 = count_neg_zeros_pos(df_skill_measure1_below_50['sample_luck2'])
table = pd.DataFrame(
{'sample_luck1': [sl1[0],sl1[1],sl1[2]], 'sample_luck2': [sl2[0],sl2[1],sl2[2]]},
index = ['negatives', 'zeros', 'positives']
)
table
Deveria haver mais componentes de sorte negativos no semestre 1 e mais positivos para o semestre 2. Correto?
Então, vamos refletir sobre o que fizemos até o momento.
- Simulamos dois experimentos (um no semestre 1 e outro no semestre 2) que medem a performance dos jogadores. Existem imperfeições (ruídos) nestas medições (ou seja, elas possuem uma componente aleatória de sorte).
- Selecionamos uma amostra assimétrica com base no desempenho observado em um dos experimentos (selecionamos jogadores com $\text{skill_measure1} < 50$). Mesmo que nada tenha sido feito com este grupo de jogadores (nenhuma política nova de treino), quando realizamos um novo experimento de medição no segundo semestre, descobrimos que os jogadores apresentaram uma pequena melhora no desempenho.
Se você fosse o treinador deste grupo de jogadores e tivesse sugerido a necessidade de uma nova metodologia de treinamento com base nos resultados observados no primeiro semestre (sample_skill_measure1), então, caso nada tivesse sido feito por você, as pessoas poderiam começar a questionar a sua sugestão de uma nova metodologia de treinamento, uma vez que ocorreu um melhora no segundo semestre sem a adoção de nenhuma nova política de treinamento. Digamos que você decidiu mostrar para estas pessoas que o ganho aparente deste grupo de jogadores não seja de fato um ganho real de desempenho. Então, você decide que analisará a mudança de desempenho entre o primeiro e segundo semestres para os jogadores que tiveram um desempenho acima da média no primeiro semestre ($\text{skill_measure1} > 50$).
is_skill_measure1_above_50 = df['skill_measure1'] > 50
df_skill_measure1_above_50 = filter_df(is_skill_measure1_above_50, df)
df_skill_measure1_above_50.head()
Desta vez, geramos uma amostra (a partir da nossa população) que compreende apenas jogadores tais que $\text{skill_measure1} > 50$. Novamente, trata-se de uma amostra não aleatória.
Se compararmos o desempenho somente destes jogadores da nossa amostra entre o primeiro e segundo semestres (sample_skill_measure1 e sample_skill_measure2), teremos:
df_skill_measure1_above_50[['sample_skill_measure1', 'sample_skill_measure2']].describe()
O que aconteceu desta vez? Parece que o grupo de jogadores acima da média no primeiro semestre apresentou uma piora no desempenho do primeiro para o segundo semestre. Agora, aquelas pessoas que criticaram a sua sugestão de um novo programa de treinamento estão realmente convencidos (ou deveríamos dizer, confusos?). Elas argumentaram que os jogadores de baixo desempenho no primeiro semestre melhoraram mesmo sem qualquer programa especial de treinamento, mas os jogadores de alto desempenho pioraram. Talvez as pessoas digam que você deveria aplicar o seu programa especial de treinamento nos jogadores que apresentaram alto desempenho no primeiro semestre, para evitar mais pioras futuras de desempenho.
O que está acontecendo aqui? O que você testemunhou aqui novamente foi o fenômeno estatístico chamado regressão à média (regression to the mean). Isto ocorre em parte porque as medições realizadas são imperfeitas (possuem ruidos).
No nosso exemplo, os experimentos de medição revelam parcialmente a habilidade verdadeira dos jogadores, pois eles também capturam os ruídos (no nosso exemplo, a componente de sorte). Para qualquer jogador, a componente da sorte pode funcionar a favor ou contra, o jogador pode ter um dia bom (ou seja, sorte positiva) ou um dia ruim (sorte negativa). Se teve um dia ruim, então, a medição resultante do experimento será inferior à sua habilidade verdadeira, ao passo que, se teve um dia bom, a medição resultante do experimento estará acima da sua habilidade real.
Quando selecionamos um grupo de jogadores com desempenho abaixo da média da população de $500$ jogadores, foram escolhidos muitos jogadores que realmente apresentavam habilidade abaixo da média, mas também foram selecionados jogadores cujo resultado da medição de habilidade foi abaixo da média porque estavam num dia ruim (ou seja, a componente da sorte negativa). Então, quando foi realizado um segundo experimento de medição com estes mesmos jogadores, a habilidade real dos mesmos permaneceu a mesma, mas a chance de terem um dia tão ruim quanto tiveram no primeiro experimento é bem menor. Logo, é esperado que no segundo experimento (sample_skill_measure2) este grupo de jogadores apresente uma média melhor do que a da medição do primeiro experimento.
Também é possível que, ao repetirmos estas mesmas simulações de antes, eventualmente, os resultados não ocorram como descrevi aqui. Isto pode acontecer porque não selecionamos um grupo de jogadores com desempenho tão extremo. Vamos repetir as simulações com um grupo de jogadores com desempenho bem mais extremo do que $\text{skill_measure1} < 50$.
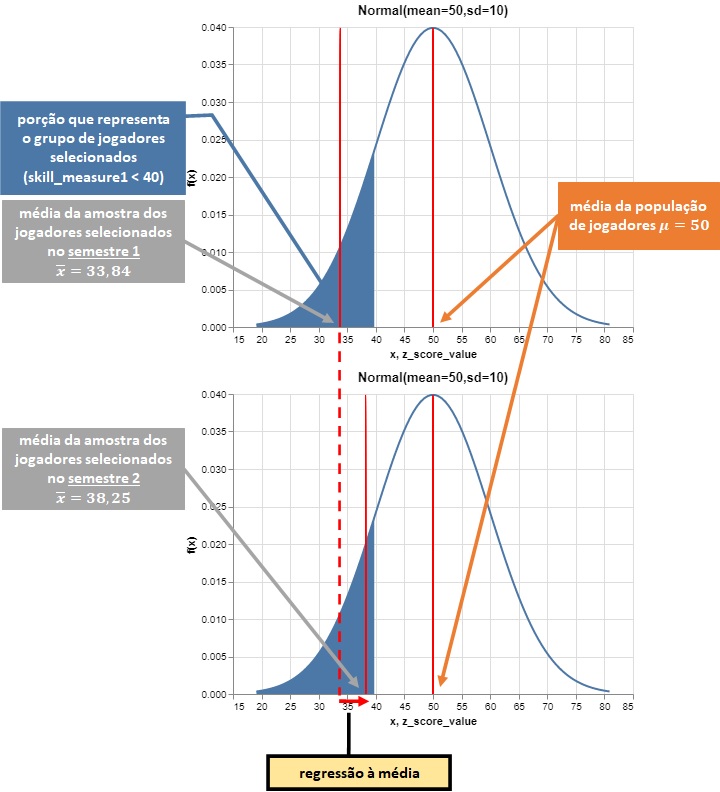
is_skill_measure1_below_40 = df['skill_measure1'] < 40
df_skill_measure1_below_40 = filter_df(is_skill_measure1_below_40, df)
df_skill_measure1_below_40.head()
Desta vez, geramos uma amostra (a partir da nossa população) que compreende apenas jogadores tais que $\text{skill_measure1} < 40$. Além de ser uma amostra não aleatória, trata-se de uma amostra bem mais extrema do que a anterior.
Vejamos as distribuições dos dois experimentos.
df_skill_measure1_below_40.hist(column='sample_skill_measure1')
df_skill_measure1_below_40.hist(column='sample_skill_measure2')


Agora, o histograma sample_skill_measure1 da nossa amostra de jogadores parece ter sido claramente cortado, já, o histograma sample_skill_measure2 não. E quanto às médias dos dois experimentos?
df_skill_measure1_below_40[['sample_skill_measure1', 'sample_skill_measure2']].describe()
Analisando as médias, é possível observar que esta amostra de jogadores apresentou um desempenho muito superior no segundo experimento se comparado ao primeiro. Os efeitos da regressão à média (regression to the mean) aqui estão mais evidentes.
Explicação da regressão à média através de uma ilustração¶
O que precisamos saber sobre regressão à média¶
Trata-se de um fenômeno estatístico
A regressão à média ocorre quando uma amostragem é realizada de forma assimétrica em relação à população. Se você fizer uma amostragem aleatória da população, observará (sujeito a erro aleatório) que a população e a sua amostra possuem a mesma média na primeira medição. Então, como a amostra já está na média da população na primeira medição, é impossível que esta média volte à média da população.
É um fenômeno de grupo
Não é possível determinar de que maneira a medição de uma característica de um indivíduo irá se mover com base na regressão à média. Embora a média do grupo se mova em direção à média da população, é provável que a medição de alguns indivíduos do grupo mova na direção oposta.
É um fenômeno relativo
Isto não tem qualquer relação com as tendências maturacionais gerais. Pode acontecer de todos na população ganharem 20 pontos (em média) entre a medição 1 e a medição 2. Mas mesmo neste caso, a regressão à média ainda pode operar, ou seja, as pessoas com baixa pontuação, em média, ganhando mais pontos do que o ganho populacional de 20 pontos (e, portanto, sua média estará mais próxima da média da população).
A regressão à média pode ocorrer para cima ou para baixo
Se uma amostra compreender pontuadores abaixo da média da população, então, o efeito da regressão à média ocasionará a percepção de que a pontuação dos mesmos melhorou na segunda medição. Porém, se uma amostra for composta por pontuadores acima da média da população, então, a percepção contrária ocorrerá.
Quanto mais extremo o grupo amostral, maior a regressão à média
Se uma amostra diferir da população apenas um pouco na primeira medida, então, não haverá muito espaço para regressão à média, pois, a média da amostra já estará próxima da média da população. Já, se uma amostra for muito extrema em relação à população, então, a média da amostra estará mais distante da média da população e haverá mais espaço para regressão à média.
Quanto menos correlacionadas as duas medições, maior o efeito da regressão à média
Outro fator que afeta o tamanho do efeito da regressão à média é a correlação entre as duas medições. Se as duas medições estiverem perfeitamente correlacionadas, então, não haverá regressão à média. No entanto, é improvável que isto ocorra na prática. Sabe-se que não existe uma medição perfeita, ou seja, assume-se que toda medida tem algum erro aleatório (algum ruído).
Resumo¶
R1. Regressão à média (regression to the mean) é um fenômeno estatístico que ocorre sempre que:
- você trabalha com uma amostra não aleatória extraída da população
- e duas variáveis imperfeitamente correlacionadas (correlação diferente de $1$ ou diferente de $-1$) são medidas.
R2. Quanto menos correlacionadas as duas variáveis, maior o efeito da regressão para a média. Além disso, quanto mais extremo for o valor da média da amostra não aleatória (quando comparada com a média da população), mais espaço haverá para regredir à média.
< Conteúdo >
![]()